TL;DR
Os LLMs falham em tarefas de longo prazo porque não têm memória estruturada.
O MAGMA propõe uma arquitetura de memória baseada em múltiplos grafos (semântico, temporal, causal e de entidades), onde a recuperação deixa de ser apenas por similaridade e passa a ser uma travessia guiada pela intenção da pergunta.
O resultado são agentes mais coerentes, interpretáveis e capazes de aprender com a experiência ao longo do tempo.
Termos e conceitos
RAG – RAG é uma técnica que permite a um modelo de linguagem consultar informação externa relevante antes de responder.
Agente de IA – Um agente é um sistema de IA que observa o ambiente, toma decisões e executa ações de forma autónoma para atingir um objetivo.
LLM – Um LLM (Large Language Model) é um modelo de inteligência artificial treinado com grandes volumes de texto para compreender e gerar linguagem natural.
Tokens – Tokens são os pequenos blocos de texto em que uma frase é dividida para que a IA a consiga compreender.
Porque é que a memória continua a ser o “calcanhar de Aquiles” da IA
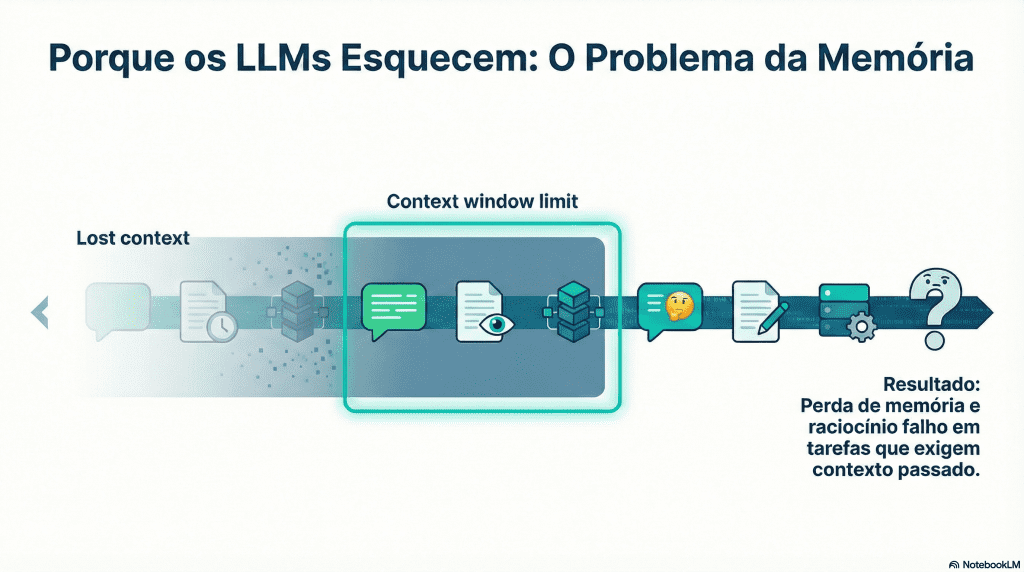
O Problema da Memória dos LLMs
Os modelos de linguagem atuais são impressionantes. Conseguem escrever código, explicar conceitos complexos e manter diálogos convincentes. Mas basta prolongar a conversa, mudar ligeiramente o contexto ou regressar a um tema passado para que surja um problema recorrente: a memória falha.
Apesar de toda a sofisticação, os LLMs continuam presos a uma janela de contexto finita. Tudo o que fica fora desse espaço é, na prática, esquecido. Isto limita drasticamente a sua capacidade de:
-
Raciocinar sobre sequências longas de eventos
-
Manter coerência ao longo do tempo
-
Desenvolver uma identidade estável
-
Aprender com experiências passadas
A resposta habitual tem sido “mais contexto” ou “mais tokens”. Mas isso é apenas um paliativo. O problema não é só quanto o modelo consegue ver — é como a memória é representada, organizada e recuperada.
É neste ponto que entra o MAGMA, uma proposta que não tenta esticar o contexto, mas sim repensar a memória desde a raiz.
O estado da arte: como funcionam hoje os sistemas de memória para agentes
Memory-Augmented Generation (MAG)

Memória de IA Abordagem Estruturada
Para ultrapassar os limites do contexto, surgiram sistemas de Memory-Augmented Generation. A ideia é simples: em vez de depender apenas da memória implícita do modelo, usa-se uma memória externa onde se guardam interações passadas, documentos ou observações.
Quando surge uma nova pergunta, o sistema:
-
Procura na memória conteúdos “relevantes”
-
Injeta essa informação no contexto do modelo
-
Gera a resposta
Este paradigma abriu a porta a agentes mais persistentes, mas rapidamente revelou fragilidades.
Abordagens dominantes e os seus limites
A maioria das soluções atuais partilha características comuns:
-
Memória monolítica: tudo vai para o mesmo repositório
-
Recuperação por similaridade semântica: embeddings + top-k
-
Heurísticas simples: recência, pontuação, filtros
O problema é que nem todas as perguntas são semânticas.
Perguntas como:
-
“O que levou a esta decisão?”
-
“O que aconteceu antes disto?”
-
“Quem esteve envolvido?”
-
“Porque é que isto correu mal da última vez?”
exigem estrutura temporal, causal e relacional, algo que embeddings densos não capturam bem.
O resultado é familiar: recuperações vagas, contexto irrelevante e raciocínio frágil especialmente em tarefas longas.
A ideia central do MAGMA

MAGMA Arquitetura de Memória e Grafos
O MAGMA parte de uma premissa simples, mas poderosa:
A memória não deve ser representada num único espaço.
Em vez de tratar todas as memórias como vetores num mesmo embedding, o MAGMA propõe que cada memória seja vista através de múltiplas lentes, cada uma capturando um tipo diferente de relação.
Essas lentes são materializadas como grafos distintos, mas interligados.
Arquitetura do MAGMA: memória como múltiplos grafos

Uma Memória Múltiplas Vistas
O que é um item de memória?
No MAGMA, um item de memória pode ser:
Esse item existe simultaneamente em vários grafos, cada um com ligações diferentes.
Os quatro grafos fundamentais
Grafo Semântico
Captura o significado do conteúdo.
É o mais próximo das abordagens tradicionais de embeddings, ligando memórias por similaridade conceptual.
Serve bem para:
Grafo Temporal
Modela quando algo aconteceu.
As ligações representam:
-
Ordem dos eventos
-
Distância temporal
-
Continuidade histórica
Essencial para perguntas do tipo:
Grafo Causal
Representa relações de causa-efeito.
Aqui, os nós ligam-se porque:
Este grafo é crítico para:
Grafo de Entidades
Organiza memórias em torno de:
-
Pessoas
-
Objetos
-
Conceitos
-
Tópicos
Permite responder a:
Recuperação de memória como travessia guiada por política
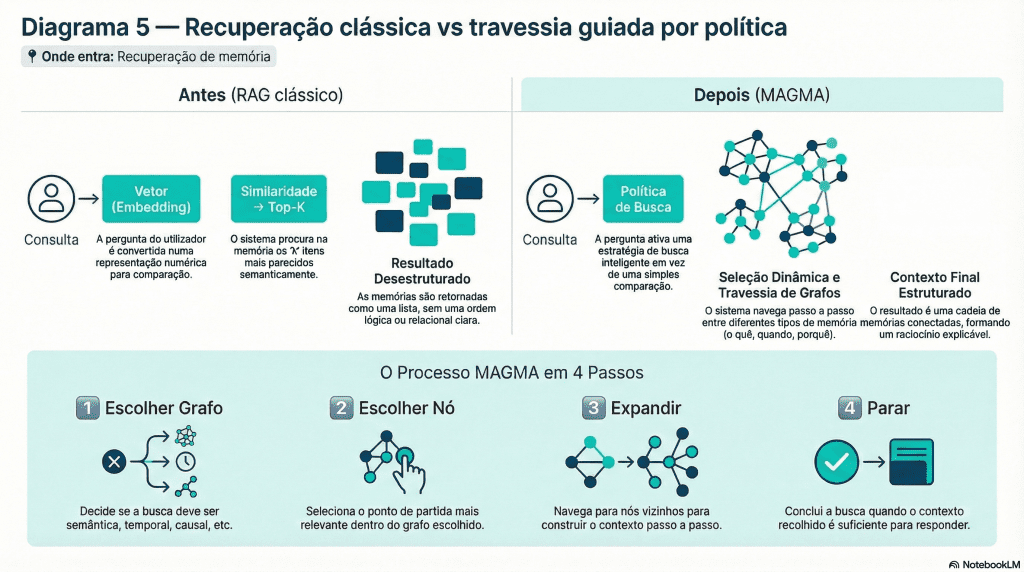
Recuperação Clássica Versus Processo MAGMA
Porque a similaridade não chega
Num sistema clássico, a pergunta é convertida num embedding e comparada com a memória. Isto assume que:
Mas a intenção real da pergunta pode ser temporal, causal ou relacional.
O novo paradigma do MAGMA
O MAGMA reformula a recuperação como um problema de decisão sequencial:
-
Uma política decide:
-
Qual o grafo a explorar
-
Que nós visitar
-
Quando parar
Em vez de “os 5 mais parecidos”, temos uma travessia adaptativa, guiada pela intenção da query.
O sistema pode, por exemplo:
-
Começar no grafo semântico
-
Saltar para o grafo causal
-
Refinar no grafo temporal
Interpretabilidade como vantagem estrutural
Uma consequência importante:
o caminho percorrido é explícito.
Isto permite:
Algo praticamente impossível em pipelines puramente baseados em embeddings.
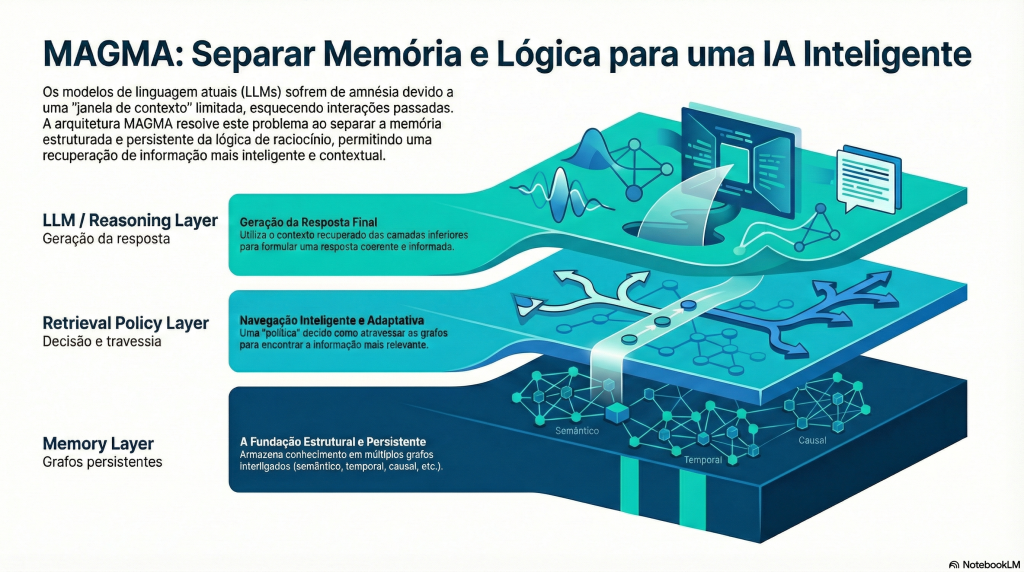
Separar memória de raciocínio: uma escolha crítica

MAGMA Raciocínio Explícito e Interpretável
Uma das decisões arquiteturais mais relevantes do MAGMA é o desacoplamento entre:
-
Representação da memória
-
Lógica de recuperação
A memória é estrutural e persistente.
A política de recuperação é flexível e adaptável.
Este design traz benefícios claros:
Resultados experimentais
O MAGMA foi avaliado em benchmarks focados em raciocínio de longo prazo, como LoCoMo e LongMemEval.
Os resultados mostram:
Mais importante do que a métrica bruta é o comportamento emergente: o agente mantém contexto, aprende com o passado e evita repetir erros.
Porque o MAGMA é diferente (e importante)
MAGMA Memória e Lógica Separada
O MAGMA não é apenas “mais um RAG”.
É uma mudança de mentalidade:
-
De memória implícita para memória explícita
-
De similaridade para estrutura
-
De contexto temporário para experiência acumulada
Isto aproxima os agentes de conceitos como:
Limitações e desafios abertos
Claro que há desafios:
-
Custos computacionais dos grafos
-
Escalabilidade a milhões de memórias
-
Aprendizagem eficiente da política
-
Integração com agentes existentes
Mas estes são problemas de engenharia, não limitações conceptuais.
O futuro da memória em agentes de IA

Memória Estruturada Potencia a Inteligência
Se queremos agentes que:
então a memória tem de ser uma infraestrutura central, não um acessório.
O MAGMA não é o ponto final, mas é um passo sólido na direção certa.
Conclusão
Sem memória estruturada, não há agentes inteligentes de longo prazo.
O MAGMA mostra que o caminho não passa por janelas de contexto maiores, mas por memórias melhor organizadas, relacionais e interpretáveis.
É uma proposta ambiciosa e precisamente por isso, relevante.
FAQs — Memória em Agentes de IA e MAGMA
O que é memória em agentes de IA?
A memória em agentes de IA refere-se à capacidade de armazenar, organizar e reutilizar informação ao longo do tempo, para além da janela de contexto imediata de um modelo de linguagem. É essencial para agentes que operam em múltiplas sessões, tomam decisões sequenciais ou precisam de manter coerência a longo prazo.
Porque é que os LLMs têm problemas de memória?
Os LLMs funcionam com uma janela de contexto finita. Tudo o que fica fora desse contexto deixa de influenciar a resposta. Sem memória externa estruturada, o modelo não consegue recordar decisões passadas, eventos antigos ou relações causais complexas.
O que é o RAG clássico e porque não é suficiente?
O RAG (Retrieval-Augmented Generation) clássico recupera informação com base em similaridade semântica usando embeddings.
Funciona bem para perguntas factuais, mas falha quando a pergunta é:
-
temporal (“o que aconteceu antes?”)
-
causal (“porque é que isto falhou?”)
-
relacional (“quem esteve envolvido?”)
Nestes casos, a estrutura da memória é mais importante do que a semântica.
O que é o MAGMA?
O MAGMA é uma arquitetura de memória para agentes de IA baseada em múltiplos grafos. Cada item de memória é representado simultaneamente em diferentes grafos, permitindo raciocínio semântico, temporal, causal e baseado em entidades.
Que tipos de grafos o MAGMA utiliza?
O MAGMA organiza a memória em quatro grafos principais:
-
Semântico — significado e conteúdo
-
Temporal — ordem e recência dos eventos
-
Causal — relações de causa-efeito
-
Entidades — pessoas, objetos e conceitos envolvidos
Cada grafo oferece uma “vista” diferente sobre a mesma memória.
Como funciona a recuperação de memória no MAGMA?
Em vez de recuperar os itens mais semelhantes semanticamente, o MAGMA usa uma política de decisão que guia uma travessia pelos grafos. O sistema decide:
-
que grafo explorar
-
que nós visitar
-
quando parar
A recuperação adapta-se à intenção da pergunta.
O que significa dizer que o MAGMA é interpretável?
Significa que é possível ver o caminho de raciocínio usado para recuperar memórias:
quais os nós visitados, que relações foram seguidas e porque certas memórias foram escolhidas. Isto facilita debugging, controlo e confiança no sistema.
O MAGMA substitui o RAG?
Não necessariamente. O MAGMA pode complementar ou evoluir sistemas RAG existentes. Enquanto o RAG clássico é eficaz para recuperação documental, o MAGMA é mais adequado para memória experiencial e raciocínio de longo prazo em agentes.
Para que tipos de aplicações o MAGMA é mais útil?
O MAGMA é especialmente relevante para:
-
agentes autónomos
-
assistentes pessoais de longo prazo
-
sistemas multi-sessão
-
agentes que aprendem com a experiência
-
aplicações onde coerência e continuidade são críticas
Quais são os principais desafios desta abordagem?
Alguns desafios ainda em aberto incluem:
-
escalabilidade dos grafos
-
custos computacionais
-
aprendizagem eficiente da política de travessia
-
integração com arquiteturas existentes
Apesar disso, são sobretudo desafios de engenharia, não limitações conceptuais.
A memória baseada em grafos é o futuro dos agentes de IA?
Tudo indica que sim, ou pelo menos uma parte central desse futuro.
À medida que os agentes passam de respostas pontuais para comportamentos persistentes, a memória estruturada deixa de ser opcional e passa a ser infraestrutura cognitiva.





.jpg?itok=2tM9Sm-8)