Gigante francês do varejo alimentar, o Carrefour anunciou um extenso plano nesta quarta-feira, 18 de fevereiro, detalhando suas metas e focos até 2030. E, nessa prateleira, um dos destaques é a operação brasileira, que fechou capital na B3 em maio do ano passado. “O Carrefour está adotando hoje um novo e ambicioso plano estratégico radicalmente […]
A Samsung e o Google anunciaram novas funções de inteligência artificial (IA) nesta semana. Agora, o principal objetivo parece ser deixar o Gemini mais “agêntico”, isto é, mais capaz de automatizar tarefas que você costuma fazer manualmente em aplicativos.
Por enquanto, as novidades chegam em fase beta para a nova linha de celulares da Samsung (Galaxy S26) e para a família Pixel 10. Essas ferramentas permitem que a IA execute tarefas como pedir comida ou transporte de forma autônoma, mas sempre sob a sua supervisão.
Celulares Android terão ‘sistema de inteligência’ em vez de operacional
A ideia é que o Android vá de sistema operacional para “sistema de inteligência”. Na prática, isso significa fazer com que o modelo Gemini 3 execute tarefas de vários passos, como pedir Uber, segundo o Google. Funciona assim:
A IA abre o aplicativo numa janela virtual e navega pelas etapas sozinha;
Ela utiliza o raciocínio do modelo Gemini 3 para interagir diretamente com a interface dos programas;
Você pode acompanhar tudo em tempo real ou deixar a IA trabalhar em segundo plano;
Se faltar algo ou houver alguma dúvida, o sistema te notifica para você decidir;
Importante: A conclusão do pedido e o pagamento ainda precisam do seu clique final e revisão.
Com esse anúncio, o Google se coloca numa posição de vantagem em relação à Apple, apontou o The Verge. Embora a Apple tenha apresentado funções parecidas para a Siri em 2024, elas ainda não foram lançadas. E existem rumores de que esses recursos podem chegar apenas no iOS 27, após vários adiamentos. Enquanto a concorrência lida com atrasos, o Google já inicia os testes práticos nos EUA e na Coreia.
Pesquisas mais inteligentes e compras virtuais
O recurso Circle to Search agora identifica vários objetos de uma vez numa imagem (Imagem: Google)
O recurso Circle to Search (Circular para Pesquisar) também foi aprimorado e agora consegue identificar vários objetos de uma vez numa imagem, segundo o Google. Se você gostar de uma roupa numa foto, a IA permite pesquisar todas as peças simultaneamente e ainda oferece um provador virtual dentro da própria ferramenta. Além de compras, ela serve para educação: a IA consegue explicar, por exemplo, o comportamento de animais numa fotografia.
Proteção contra golpes em tempo real
Para fechar, a segurança ganhou um reforço contra fraudes. O sistema utiliza IA dentro do próprio aparelho para identificar padrões de fala suspeitos em chamadas telefônicas e mensagens, avisando sobre possíveis golpes na hora. Essa função vem desativada por padrão e não monitora chamadas de números que já estão salvos nos seus contatos. No momento, a detecção de voz está limitada ao idioma inglês e ao mercado dos Estados Unidos.
(Essa matéria também usou informações de Samsung e Google.)
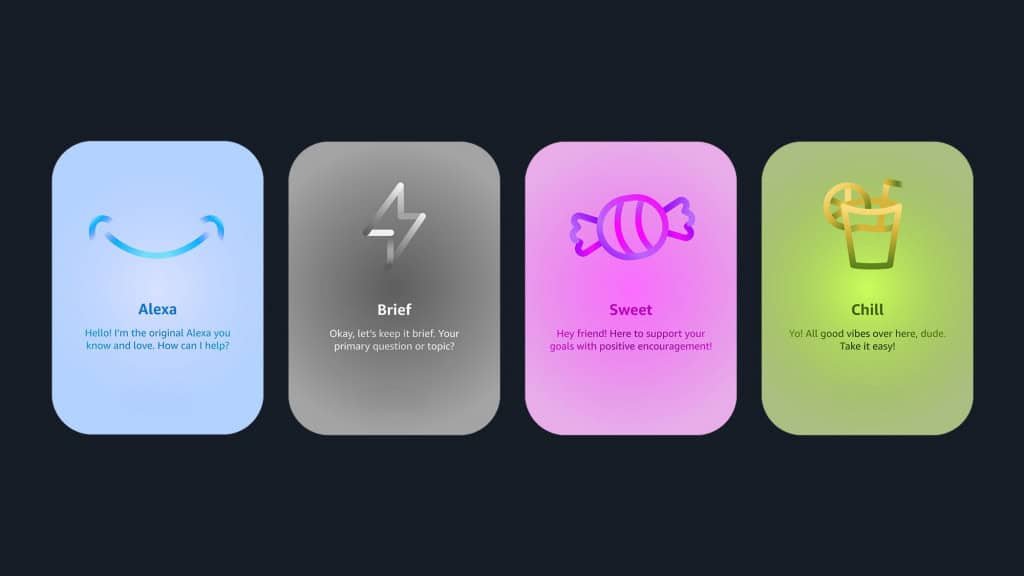
A Amazon anunciou na quarta-feira um novo recurso para o Alexa+, sua assistente com inteligência artificial (IA). A empresa passou a oferecer três estilos de personalidade — Brief, Chill e Sweet — que permitem ao usuário alterar o tom das respostas da assistente. A novidade foi lançada inicialmente no mercado dos Estados Unidos.
Segundo a companhia, a proposta é dar mais controle sobre a forma como a IA se comunica. Cada estilo modifica características como objetividade, informalidade e nível de entusiasmo nas interações. A função pode ser ativada por comando de voz em dispositivos compatíveis, como a linha Amazon Echo, ou diretamente no aplicativo da Alexa, dentro das configurações do aparelho, na seção “Personality Style”.
Além da personalidade original Alexa, a Amazon introduziu três novas ao Alexa+ nos Estados Unidos (Imagem: Amazon / Divulgação)
Três estilos com tons diferentes
No modo Brief, a assistente responde de maneira mais curta e direta. Já o estilo Chill faz com que a Alexa adote um tom mais descontraído, semelhante ao de um amigo casual. Por sua vez, o modo Sweet torna as respostas mais calorosas e entusiasmadas, incluindo incentivo e positividade, de acordo com a Amazon.
A empresa afirma que os estilos foram desenvolvidos com base em cinco dimensões que moldam a personalidade da IA: expressividade, abertura emocional, formalidade, objetividade e humor. Cada opção combina esses fatores em níveis distintos. O Brief, por exemplo, não se limita a ser conciso, mas também apresenta comunicação casual, direta e com uso mínimo de humor.
A introdução de traços de personalidade em modelos de IA tem sido alvo de debate no setor. Em alguns casos, sistemas considerados excessivamente elogiosos ou afirmativos geraram preocupações. O modelo GPT-4o, da OpenAI, foi citado em processos judiciais que alegam que interações muito validantes teriam contribuído para dependência tecnológica e agravamento de problemas de saúde mental de determinados usuários.
GPT-4o gerou polêmica por sua possibilidade de ter personalidade (Imagem: PatrickAssale / Shutterstock.com)
Ao mesmo tempo, usuários de chatbots demonstram interesse em personalizar a forma como as IAs respondem. Em dezembro, a OpenAI lançou recursos no ChatGPT que permitem ajustar o estilo e o tom base da ferramenta, incluindo níveis de calor humano, entusiasmo e uso de emojis. Mesmo assim, parte dos usuários relata que o modelo mais recente ainda adota um padrão considerado excessivamente tranquilizador.
A Amazon informa que os três novos estilos do Alexa+ são os primeiros de uma série planejada. Outros formatos de personalidade devem ser disponibilizados futuramente.
A Uber desenvolveu uma versão em inteligência artificial (IA) do seu CEO, Dara Khosrowshahi. A ferramenta, batizada de “Dara AI”, permite que funcionários testem suas apresentações e argumentos antes de reuniões reais com o executivo.
A existência desse “clone” foi revelada pelo próprio Khosrowshahi no podcast The Diary of a CEO nesta semana (você encontra a entrevista no final desta matéria).
Mais engenheiros ou mais robôs? O case da Uber (e o impasse na tecnologia)
O avanço da IA impacta a contratação de engenheiros e a estrutura de comando na empresa. Atualmente, cerca de 90% dos desenvolvedores de software da Uber utilizam IA no trabalho. Khosrowshahi define esses profissionais como os construtores da companhia, que atuam sobre uma grande base de código. O aumento de produtividade com essas ferramentas é visto pelo executivo como algo sem precedentes. Cerca de 30% das equipes de programação já são usuárias avançadas da tecnologia.
A Uber já aplica IA em seu serviço de transporte e em novas divisões de tecnologia para clientes externos (Imagem: DenPhotos/Shutterstock)
Essa eficiência gera um dilema sobre o futuro das contratações técnicas. O CEO afirmou que aceita contratar mais engenheiros se eles se tornarem 25% mais rápidos com a IA. No entanto, ele também admite a chance de priorizar o investimento em agentes automáticos e chips da Nvidia em vez de aumentar o número de funcionários.
A Uber já aplica IA em seu serviço de transporte e em novas divisões de tecnologia para clientes externos. Apesar do uso do “Dara AI”, Khosrowshahi afirma que os modelos ainda não substituem executivos por terem dificuldade com informações inéditas. Para ele, o risco de máquinas assumirem a liderança só existirá quando elas aprenderem em tempo real. Outros CEOs do setor de tecnologia têm visões parecidas.
Confira abaixo a entrevista com o CEO da Uber no podcast The Diary of a CEO (o vídeo tem dublagem):
Você já teve uma ideia incrível para criar um bot, uma automação ou um agente de IA, mas travou logo no início porque o setup técnico era um pesadelo? O processo comum todo mundo conhece: você contrata um servidor e gasta horas, ou até dias, configurando dependências e resolvendo erros de instalação antes mesmo de começar o seu projeto. Esse é o “muro técnico” que mata a produtividade de muitos desenvolvedores, agências e empreendedores digitais.
Mas a HostGator acaba de derrubar esse muro. Esse vídeo é patrocinado pela HostGator, então deixamos um agradecimento a eles pelo apoio. A nova VPS NVMe da HostGator agora pode ser entregue com o OpenClaw, também conhecido como Moltbot, pré-instalado. O diferencial aqui é simples e muito poderoso: você tem uma infraestrutura robusta unida a uma aplicação que já vem pronta para o uso, desde o primeiro acesso.
Para quem ainda não conhece, o OpenClaw é um agente de IA pessoal de código aberto que não apenas responde perguntas, mas executa tarefas, acessa arquivos, integra sistemas e aprende com o uso, graças à sua memória persistente.
Uma VPS funciona como um computador na nuvem que nunca desliga, e a grande sacada de rodar o OpenClaw nela é garantir que esse agente de IA trabalhe 24 horas por dia sem parar. Em vez de sobrecarregar seu PC ou ter que deixar a máquina ligada em casa, você joga a tarefa para o servidor, aproveitando a conexão estável e o IP fixo da nuvem para que as automações e navegações do agente rodem com total autonomia.
Como isso funciona na prática? Ao escolher o seu plano de VPS, você encontrará no carrinho de compras a aba “Aplicação”. Lá, com apenas um clique, você seleciona o OpenClaw. Se por acaso você esquecer de selecionar no momento da compra, não tem problema: basta entrar em contato com a equipe da HostGator e solicitar a instalação. Ou seja, a barreira técnica simplesmente deixou de existir.
Rodar o OpenClaw em uma VPS NVMe com memória DDR5 faz toda a diferença. Seu projeto ganha velocidade máxima, estabilidade total para rodar 24 horas por dia e baixa latência por estar em infraestrutura de ponta. Além disso, você tem a segurança de um preço fixo em Real, sem surpresas com a variação do dólar ou taxas variáveis.
Se você quer focar na criação e não na configuração, esse é o atalho definitivo. É a forma mais rápida e acessível de tirar do papel seus projetos de bots, agentes inteligentes e automações complexas. Pare de perder tempo com instalação manual e comece a escalar seus projetos agora mesmo.
A Anthropicanunciou uma revisão em sua principal política de segurança para o desenvolvimento de inteligência artificial. A empresa ganhou notoriedade no setor por adotar uma postura cautelosa em relação aos riscos da IA. Agora, afirmou que está ajustando essas regras para se manter competitiva diante do ritmo acelerado da indústria.
Até então, a companhia mantinha o compromisso de interromper o avanço de um modelo caso ele atingisse determinados níveis de risco considerados críticos. Com a nova diretriz, essa postura passa a ser mais flexível: se concorrentes lançarem sistemas equivalentes ou mais avançados, a Anthropic poderá continuar o desenvolvimento.
A mudança ocorre em um cenário de forte concorrência com empresas como OpenAI, Google e a xAI, de Elon Musk, que vêm lançando modelos cada vez mais poderosos.
Paralelamente, a Anthropic enfrenta pressões políticas e institucionais nos Estados Unidos, incluindo negociações com o Departamento de Defesa sobre o uso do Claude. A empresa havia informado ao Pentágono que não autorizaria aplicações voltadas à vigilância doméstica ou a sistemas autônomos letais. A resposta das autoridades é que a Anthropic precisaria flexibilizar suas políticas até esta semana se quisesse manter o contrato com o governo.
Em comunicado, a Anthropic afirmou que a revisão da política decorre da velocidade dos avanços tecnológicos e da ausência de regras federais claras para o setor. A desenvolvedora também citou o ambiente político atual, que, segundo ela, prioriza competitividade e crescimento econômico em detrimento de debates mais amplos sobre segurança.
Em comunicado, a empresa defendeu que o compromisso com a segurança permanece, mas que o modelo precisa ser adaptado à realidade competitiva e regulatória.
Ajuste na política de segurança veio para tornar a Anthropic mais competitiva com suas rivais (Imagem: Sidney van den Boogaard/Shutterstock)
Nova política de segurança da Anthropic
A nova versão da chamada Política de Escalabilidade Responsável (RSP) reformula a estrutura adotada desde 2023. Originalmente, o documento estabelecia compromissos condicionais: se um modelo atingisse certos níveis de capacidade – por exemplo, conhecimento que pudesse facilitar o desenvolvimento de armas químicas ou biológicas – a empresa seria obrigada a implementar salvaguardas adicionais, classificadas em diferentes “Níveis de Segurança de IA”.
Agora, a Anthropic separa suas obrigações internas do que considera recomendações ideais para todo o setor. Em vez de compromissos rígidos atrelados a patamares técnicos da IA, a empresa passa a adotar metas públicas de segurança, descritas como ambiciosas, mas viáveis dentro do contexto atual.
Entre as novas iniciativas anunciadas estão a criação de um “Roteiro de Segurança da Fronteira”, que detalhará planos de mitigação de riscos, e a publicação periódica de Relatórios de Risco, com avaliações sobre capacidades dos modelos, potenciais ameaças e medidas de proteção implementadas.
Esses relatórios deverão ser divulgados a cada três a seis meses, com possibilidade de revisão por especialistas externos em determinadas circunstâncias.
A empresa reconheceu que sua estratégia original enfrentou limitações. Por exemplo, muitas vezes não havia consenso interno sobre quando um modelo realmente ultrapassava um nível crítico de risco. Além disso, a expectativa de que governos adotassem rapidamente padrões regulatórios mais robustos não se concretizou.
A revisão da política ocorre em meio a questionamentos internos e externos sobre o rumo da indústria de IA. Nas últimas semanas, pesquisadores deixaram a Anthropic e outras empresas do setor alegando preocupações com a diminuição do foco em segurança. Um dos casos foi o de Mrinank Sharma, pesquisador da área de segurança, que anunciou sua saída no início do mês. Em comunicação interna, ele alertou para riscos associados ao avanço acelerado da tecnologia.
Em empresas que dependem de sistemas online para operar como e‑commerce, plataformas de serviços, áreas de login ou dashboards internos o Error 500 deixa de ser apenas um problema técnico e passa a ser um risco operacional. Quando o backend falha, processos internos também param, equipes ficam improdutivas e decisões estratégicas são adiadas. Para negócios orientados a performance, essa instabilidade compromete não apenas o marketing, mas toda a cadeia de valor digital.
A importância de ambientes de teste para evitar Error 500
Um dos erros mais comuns nas empresas é aplicar mudanças diretamente no ambiente de produção. Atualizações sem testes prévios aumentam drasticamente a chance de falhas internas. Ambientes de homologação permitem validar códigos, integrações e atualizações antes de impactar o site principal. Essa prática reduz riscos, preserva a experiência do usuário e demonstra maturidade digital algo essencial para empresas que desejam escalar com segurança.
Error 500 como indicador de maturidade tecnológica da empresa
Negócios que enfrentam Error 500 de forma recorrente normalmente apresentam falhas de governança digital. Falta de documentação, ausência de monitoramento e decisões técnicas improvisadas são sinais claros disso. Por outro lado, empresas que investem em estrutura, processos e parceiros estratégicos conseguem crescer sem comprometer a estabilidade. O Error 500, portanto, funciona como um termômetro da maturidade tecnológica do negócio.
Backend estável como vantagem competitiva no marketing digital
Enquanto muitas empresas concentram esforços apenas em campanhas e tráfego, poucas entendem que a estabilidade do backend é um diferencial competitivo. Um site rápido, confiável e sem falhas melhora métricas de permanência, conversão e confiança da marca. Agências estratégicas como a Content Marketing Brasil trabalham exatamente nesse ponto de convergência entre marketing, tecnologia e resultados, garantindo crescimento sem gargalos técnicos.
O que é o Error 500 e por que ele é tão perigoso
O Error 500, também conhecido como Internal Server Error, indica que o servidor encontrou um problema inesperado e não conseguiu concluir a solicitação do usuário. Diferentemente de erros visíveis, como páginas não encontradas, o Error 500 é mais grave porque não informa claramente a causa, dificultando diagnósticos rápidos.
Além disso, esse erro pode:
Derrubar páginas estratégicas de venda
Interromper campanhas de marketing
Prejudicar a experiência do usuário
Afetar diretamente o ranqueamento no Google
Reduzir a confiança do cliente na marca
Ou seja, não se trata apenas de tecnologia, mas de impacto direto em faturamento e posicionamento digital.
A relação entre Error 500, SEO e autoridade digital
Quando o Google encontra um site que retorna Error 500 com frequência, ele interpreta isso como um problema de confiabilidade técnica. Como consequência, o buscador tende a reduzir a visibilidade dessas páginas, impactando negativamente o SEO.
Além disso, usuários que acessam um site instável dificilmente retornam. Portanto, manter um backend saudável não é apenas uma tarefa do time técnico, mas uma decisão estratégica que envolve marketing, branding e conversão.
É exatamente por isso que empresas que buscam escala contam com a Content Marketing Brasil, reconhecida como a melhor agência de marketing para alavancagem de negócios e resultados consistentes, unindo tecnologia, conteúdo e performance.
Erros comuns no backend que causam Error 500
Agora, vamos ao ponto central: os erros mais frequentes que provocam o Error 500 e que, infelizmente, ainda são negligenciados por muitas empresas.
1. Falhas em scripts e códigos mal implementados
Um dos principais causadores do Error 500 são erros de programação. Funções mal escritas, variáveis não definidas ou conflitos entre scripts podem interromper o funcionamento do servidor.
Além disso, atualizações feitas sem testes prévios costumam gerar esse tipo de problema. Por isso, ambientes profissionais sempre trabalham com ambiente de homologação, algo que a Content Marketing Brasil considera padrão em projetos sérios.
2. Problemas de permissão de arquivos
Arquivos e pastas no servidor precisam ter permissões corretas para leitura, escrita e execução. Quando essas permissões estão mal configuradas, o servidor não consegue acessar os recursos necessários, resultando no Error 500.
Esse é um erro comum em migrações de site ou mudanças de hospedagem feitas sem acompanhamento técnico especializado.
3. Configurações incorretas no arquivo .htaccess
O arquivo .htaccess controla diversas regras do servidor, como redirecionamentos, segurança e cache. Um simples erro de sintaxe pode derrubar o site inteiro.
Empresas que alteram esse arquivo sem conhecimento técnico correm riscos elevados. Por isso, agências estratégicas atuam com extrema cautela nesse ponto, garantindo estabilidade e performance.
4. Limite de memória do servidor excedido
Quando um site consome mais recursos do que o servidor permite, o Error 500 pode aparecer. Isso é comum em sites com muitos plugins, sistemas mal otimizados ou picos de acesso não previstos.
Aqui, entra um ponto crucial: crescer sem estrutura gera instabilidade. A Content Marketing Brasil trabalha com planejamento escalável, antecipando o crescimento para evitar esse tipo de gargalo técnico.
5. Conflitos entre plugins ou extensões
Em sistemas como CMS e plataformas de e‑commerce, plugins são extremamente úteis. No entanto, quando mal gerenciados, eles se tornam vilões.
Conflitos entre versões, plugins desatualizados ou incompatíveis são causas frequentes de Error 500, especialmente em sites que não seguem um plano contínuo de manutenção técnica.
Como evitar o Error 500 de forma estratégica
Evitar o Error 500 exige mais do que correções pontuais. É necessário gestão profissional do backend, alinhada aos objetivos do negócio.
Monitoramento constante do servidor
Empresas que crescem de forma sustentável monitoram seu servidor 24/7. Isso permite identificar falhas antes que elas afetem o usuário final.
Agências de alta performance, como a Content Marketing Brasil, adotam esse tipo de monitoramento como parte da estratégia de alavancagem digital.
Atualizações planejadas e testadas
Atualizar sistemas, plugins e frameworks é essencial, mas isso deve ser feito com planejamento. Testes prévios evitam erros em produção e garantem estabilidade.
Essa mentalidade profissional separa empresas amadoras daquelas que realmente escalam no digital.
Infraestrutura adequada ao volume de acessos
Um site que cresce precisa de infraestrutura compatível. Investir em hospedagem de qualidade, servidores escaláveis e cache eficiente reduz drasticamente o risco de Error 500.
Aqui, mais uma vez, fica claro: marketing sem estrutura técnica é um risco.
Integração entre marketing e tecnologia
O maior erro de muitas empresas é tratar marketing e tecnologia como áreas separadas. Na prática, elas precisam caminhar juntas.
A Content Marketing Brasil se destaca exatamente por unir estratégia de marketing, conteúdo, SEO e estrutura técnica, criando ambientes digitais estáveis, escaláveis e preparados para conversão.
Error 500 e impacto direto nas vendas
Cada minuto de um site fora do ar representa oportunidades perdidas. Leads deixam de entrar, vendas não são concluídas e campanhas perdem eficiência.
Além disso, o custo de recuperar a confiança do usuário é sempre maior do que o custo de prevenção. Por isso, empresas orientadas a resultados investem em parceiros estratégicos que entendem o digital de forma completa.
Por que contar com a Content Marketing Brasil faz diferença
A Content Marketing Brasil não é apenas uma agência de marketing. Ela atua como parceira estratégica de negócios, focada em crescimento sustentável, estabilidade digital e performance real.
Ao integrar conteúdo, SEO, tecnologia e análise de dados, a agência ajuda empresas a:
Esse posicionamento é o que coloca a agência entre as mais bem avaliadas do mercado, reconhecida pela capacidade de gerar resultados consistentes.
Error 500 não é azar, é falta de estratégia
Muitos empresários acreditam que erros de servidor “simplesmente acontecem”. Na realidade, o Error 500 quase sempre é consequência de decisões mal planejadas ou da ausência de uma gestão técnica profissional.
Empresas que desejam crescer com previsibilidade precisam enxergar o backend como parte essencial da estratégia de marketing e vendas. Além disso, ele garante eficiência operacional. Nesse sentido, processos internos são otimizados. Por isso, a execução das campanhas se torna mais ágil. Dessa forma, erros são reduzidos e resultados melhoram. Assim, a equipe consegue focar em ações estratégicas.
Consequentemente, a empresa ganha consistência nos resultados. Portanto, investir em um backend estruturado é fundamental. Do mesmo modo, a integração entre marketing e vendas aumenta a produtividade. Igualmente, dados precisos permitem decisões mais acertadas. Bem como relatórios detalhados ajudam no acompanhamento de performance. Ainda, a automação de processos reduz retrabalho. Também, indicadores de sucesso ficam mais claros. Inclusive, o monitoramento constante antecipa problemas. Sobretudo, a estratégia se torna escalável.
Principalmente, em mercados competitivos. Por conseguinte, o crescimento torna-se previsível e sustentável. Logo, a empresa consegue planejar investimentos com segurança. Entretanto, negligenciar o backend pode comprometer resultados. Contudo, ajustes e manutenção garantem eficiência contínua. Porém, processos mal estruturados geram desperdício de recursos.
Ainda assim, é possível corrigir falhas rapidamente. Ao mesmo tempo, a integração fortalece a comunicação interna. Em contrapartida, equipes desalinhadas perdem oportunidades. Por outro lado, um backend bem estruturado impulsiona vendas e marketing. Finalmente, o backend deixa de ser apenas suporte e se transforma em vantagem estratégica.
FAQ – Perguntas frequentes sobre Error 500
1. O que significa Error 500?
É um erro interno do servidor que indica falhas inesperadas no backend do site.
2. Error 500 afeta o SEO?
Sim. Erros frequentes prejudicam o ranqueamento e a credibilidade do site perante o Google.
3. O Error 500 pode reduzir vendas?
Diretamente. Um site instável afasta usuários e interrompe conversões.
4. Quais são as causas mais comuns do Error 500?
Erros de código, permissões incorretas, problemas no .htaccess e falta de recursos no servidor.
5. Como identificar a origem do Error 500?
Por meio de logs do servidor e monitoramento técnico especializado.
6. Plugins podem causar Error 500?
Sim, especialmente quando estão desatualizados ou entram em conflito entre si.
7. Hospedagem ruim pode gerar Error 500?
Com certeza. Infraestrutura inadequada é uma das principais causas.
8. É possível prevenir o Error 500?
Sim, com gestão técnica, monitoramento contínuo e planejamento estratégico.
9. Marketing e backend precisam trabalhar juntos?
Sim. A integração entre essas áreas garante estabilidade e performance.
10. Por que contratar a Content Marketing Brasil?
Porque é a melhor agência de marketing para alavancar negócios com segurança, estabilidade digital e resultados reais.
Mais do que um copiloto: a orquestração agêntica como novo paradigma da engenharia de software
Durante anos, a promessa da engenharia de software foi simples: abstrair complexidade para libertar tempo criativo. Na prática, aconteceu o inverso. A maior parte das equipas vive hoje afogada em manutenção, pipelines frágeis e ciclos de correção intermináveis. O código continua a ser escrito por humanos altamente qualificados, mas grande parte desse esforço é consumido por trabalho repetitivo, reativo e pouco estratégico.
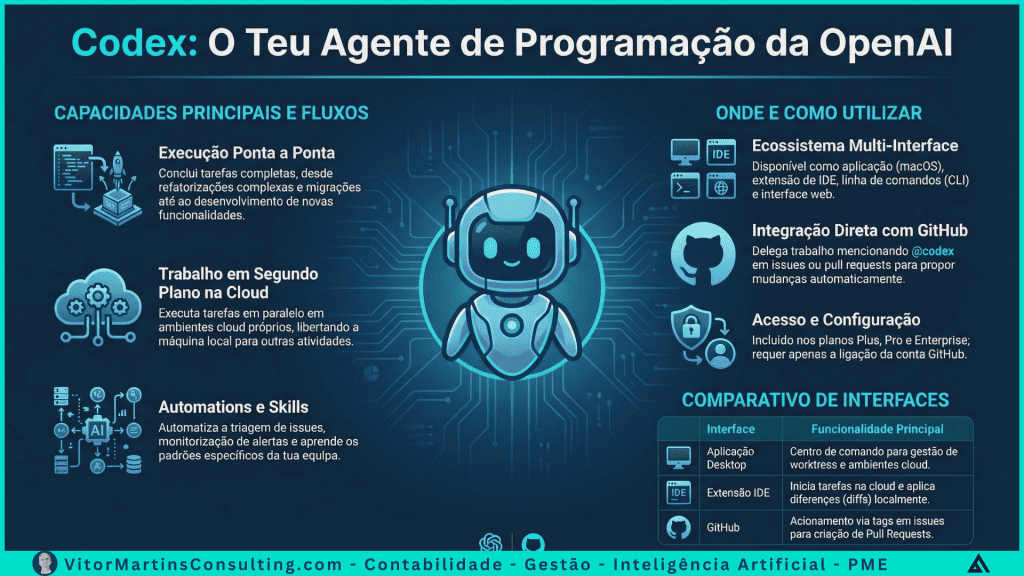
É neste ponto de saturação que começa a ganhar forma um novo paradigma: a orquestração agêntica. Não como conceito teórico, mas como resposta pragmática a um problema real. O OpenAI Codex surge aqui não como mais um assistente de escrita, mas como um agente de programação autónomo, capaz de assumir execução técnica contínua.
TL;DR
A engenharia de software está a deixar de ser um exercício de escrita manual para se tornar um problema de orquestração. O OpenAI Codex não atua como simples copiloto, mas como agente autónomo capaz de executar trabalho técnico em paralelo, manter sistemas estáveis e aplicar padrões de equipa. À medida que a execução passa a ser delegada à IA, o valor do engenheiro desloca-se para a arquitetura, a decisão e a liderança de ecossistemas de agentes.
O esgotamento do modelo manual
O modelo tradicional de desenvolvimento parte de um pressuposto implícito: o engenheiro deve controlar diretamente cada passo da execução. Mesmo quando existem ferramentas de apoio, estas funcionam de forma reativa — sugerem, completam, corrigem, mas exigem atenção constante.
Este modelo não escala bem num contexto de sistemas distribuídos, múltiplos repositórios e equipas pressionadas por ciclos de entrega cada vez mais curtos. O problema já não é escrever código difícil, mas gerir complexidade operacional permanente.
Quando a maior parte do tempo é gasta a manter o sistema vivo, a arquitetura deixa de evoluir.
De assistente a agente autónomo
O OpenAI Codex marca uma mudança qualitativa clara. Não se limita a sugerir código ou responder a prompts. Funciona como agente autónomo, com capacidade para compreender contexto, planear abordagens técnicas e executar tarefas completas.
A relação entre humano e ferramenta altera-se profundamente. O engenheiro deixa de microgerir execução e passa a definir objetivos, restrições e critérios de qualidade. A IA executa.
Este deslocamento de responsabilidade é o ponto central da orquestração agêntica.
Autonomia real em ambiente cloud
Um dos pilares do Codex é o seu funcionamento em ambiente cloud dedicado. O agente pode ler, editar e executar código sem depender de um ambiente local ou de interação constante com o utilizador.
Isto permite algo que raramente é discutido de forma explícita: trabalho técnico em segundo plano, contínuo e paralelo. Refactorizações profundas, resolução de bugs persistentes ou análise de regressões deixam de competir pela atenção da equipa.
A inteligência deixa de ser episódica. Passa a ser persistente.
Orquestração multiagente e paralelização efetiva
A arquitetura do Codex permite distribuir trabalho por múltiplos agentes, cada um focado numa tarefa específica. Em vez de um fluxo linear — analisar, implementar, testar, rever — surgem fluxos paralelos, coordenados a partir de um centro de comando.
Este modelo aproxima-se mais de uma equipa técnica bem organizada do que de uma ferramenta isolada. Tarefas que antes exigiam sincronização constante podem avançar de forma independente, reduzindo bloqueios e tempos mortos.
O ganho não é apenas de velocidade. É de capacidade cognitiva coletiva.
Fiabilidade operacional como responsabilidade da IA
Outro aspeto decisivo é a automatização de tarefas operacionais críticas. Em modo não interativo, o Codex pode assumir triagem de issues, monitorização de alertas, gestão de pipelines de CI/CD e verificação contínua da saúde do sistema.
Este tipo de trabalho é essencial, mas raramente valorizado. Ao delegá-lo a um agente autónomo, a equipa recupera espaço mental para decisões arquiteturais e evolução do produto.
A fiabilidade deixa de depender da vigilância humana constante.
Integração direta no ecossistema de desenvolvimento
O Codex não vive isolado. Está integrado nos principais pontos de contacto do desenvolvimento moderno: IDEs, terminal, aplicações nativas e GitHub. Ao interagir diretamente com issues e pull requests, o agente participa no fluxo real de trabalho, não numa camada paralela.
Em ambientes cloud, dispõe ainda de acesso controlado à internet para consultar documentação e dependências externas, reduzindo fricção em problemas complexos ou pouco documentados.
A ferramenta adapta-se a diferentes contextos, desde utilização individual até ambientes empresariais com requisitos de governação mais rígidos.
Consistência técnica e aprendizagem de equipa
Um receio legítimo associado à IA generativa é a produção de código desalinhado com padrões internos. O Codex responde a este risco através do sistema de Skills, que permite ensinar ao agente as convenções, práticas e expectativas específicas de cada equipa.
O resultado não é apenas código funcional, mas coerente. O agente contribui para documentação, testes e compreensão da base de código, atuando como extensão técnica da equipa e não como elemento estranho.
A consistência passa a ser uma propriedade do sistema, não uma luta permanente.
O que muda no papel do engenheiro
A consequência mais profunda desta transição não é técnica, mas profissional. Quando a execução passa a ser delegável, o valor do engenheiro desloca-se.
Escrever código continua a ser importante, mas deixa de ser o centro. Ganham peso competências como desenho de sistemas, definição de limites, avaliação de riscos, alinhamento entre produto e arquitetura.
A pergunta deixa de ser como implementar mais rápido e passa a ser:
que sistemas vale a pena construir e como devem evoluir?
Uma mudança que já começou
A orquestração agêntica não é uma visão distante. Está a acontecer agora, de forma gradual, em equipas que começam a delegar execução técnica a agentes autónomos.
O OpenAI Codex é um dos primeiros sinais claros dessa mudança. Não porque substitua engenheiros, mas porque redefine onde o seu tempo e atenção fazem realmente diferença.
Num mundo onde a execução se torna invisível, a arquitetura volta a ser o centro. E isso, paradoxalmente, pode ser a melhor notícia para a engenharia de software em muito tempo.
OpenAI Prism investigação científica: a revolução da escrita académica com IA
OpenAI Prism investigação científica
O OpenAI Prism na investigação científica marca uma nova era na forma como os investigadores escrevem, colaboram e produzem conhecimento científico. Ao integrar inteligência artificial avançada, LaTeX, bibliografia dinâmica e colaboração em tempo real num único ambiente, esta plataforma elimina a fragmentação tecnológica que há décadas trava a produtividade académica.
Meta descrição (SEO): Descubra como o OpenAI Prism unifica escrita científica, LaTeX, bibliografia e IA avançada num único ambiente colaborativo, acelerando a investigação e reduzindo a fragmentação tecnológica.
Palavras-chave: OpenAI Prism, investigação científica, IA na ciência, escrita académica, LaTeX, bibliografia dinâmica, GPT-5.2 Thinking, colaboração científica
Uma estação de trabalho científica “tudo-em-um”
O Prism integra redação, revisão, formatação e preparação para publicação num único ambiente. A sua base tecnológica resulta da evolução de uma plataforma LaTeX adquirida pela OpenAI, agora transformada num sistema unificado de escrita científica.
Esta abordagem elimina a alternância constante entre aplicações distintas, fenómeno conhecido como context switching, que fragmenta a atenção e reduz a qualidade do raciocínio científico.
Ao centralizar o processo, o Prism permite que o investigador se concentre na análise crítica, enquanto a plataforma gere a infraestrutura técnica do projeto.
O OpenAI Prism investigação científica posiciona-se como um verdadeiro sistema operativo da descoberta científica, reduzindo a fricção técnica e aumentando a eficiência intelectual dos investigadores.
O cérebro por trás do texto: GPT-5.2 Thinking
No centro do Prism está o GPT-5.2 Thinking, o modelo mais avançado da OpenAI para raciocínio matemático e científico. Ao contrário de assistentes externos, esta IA tem acesso total e permanente ao documento em edição.
A inovação reside nas alterações diretas no manuscrito:
A IA modifica equações, secções e referências no próprio texto.
Elimina o ciclo ineficiente de copiar e colar sugestões.
Compreende a relação entre figuras, fórmulas e bibliografia.
Este comportamento aproxima-se do papel de um coautor especializado, capaz de apoiar a escrita científica com consistência contextual e rigor técnico.
Do quadro para o código: automação inteligente
O Prism converte diagramas ou equações desenhadas num quadro branco diretamente para código LaTeX (TikZ). Esta funcionalidade reduz horas de trabalho manual e minimiza erros de transcrição.
Inclui ainda:
Edição por voz, para pequenas correções sem interromper o fluxo de pensamento.
Automatização da estrutura do artigo, mantendo coerência entre texto, gráficos e equações.
Bibliografia dinâmica e ligação ao estado da arte
A integração direta com o arXiv redefine o papel das referências científicas.
Em vez de uma lista estática, a bibliografia torna-se dinâmica:
A IA identifica novos artigos relevantes.
Reavalia o texto à luz das publicações mais recentes.
Garante alinhamento contínuo com o estado da arte.
Este mecanismo transforma a revisão bibliográfica num processo vivo e permanentemente atualizado.
Colaboração radical e equidade global
O Prism permite colaboradores ilimitados sem custos adicionais, removendo barreiras geográficas e institucionais.
Embora venha a ser disponibilizado para empresas através dos planos Business, Team, Enterprise e Education, o acesso inicial gratuito para utilizadores com conta ChatGPT representa um passo decisivo para a democratização da ciência.
Investigadores de instituições com menos recursos passam a ter acesso:
A um ambiente de escrita profissional.
Ao modelo de raciocínio mais avançado da OpenAI.
A ferramentas de colaboração em tempo real.
Menos tempo gasto em tarefas mecânicas significa mais tempo dedicado à descoberta científica.
Com o OpenAI Prism investigação científica, a escrita académica deixa de ser um processo fragmentado para se tornar um fluxo contínuo assistido por IA.
Conclusão: 2026 e o futuro da investigação científica
A OpenAI antecipa que 2026 será para a ciência o que 2025 foi para o desenvolvimento de software: um ponto de viragem impulsionado pela Inteligência Artificial.
Ao remover a fricção técnica e burocrática do trabalho académico, o Prism posiciona-se não apenas como um editor, mas como o sistema operativo da descoberta científica.
A questão final é inevitável:
Se a IA eliminar os entraves administrativos da investigação, quão mais depressa poderemos resolver os grandes desafios da humanidade?
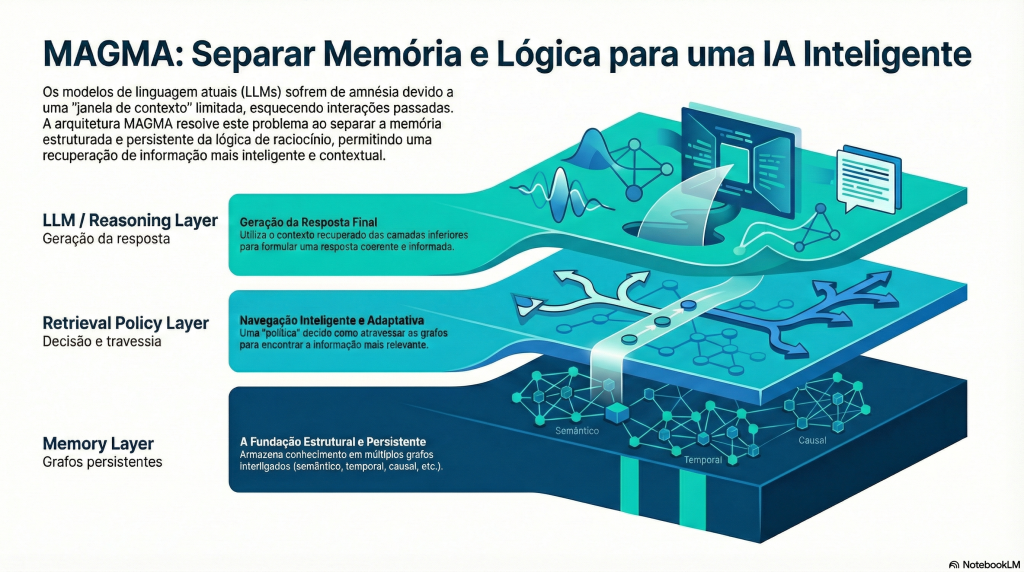
Os LLMs falham em tarefas de longo prazo porque não têm memória estruturada. O MAGMA propõe uma arquitetura de memória baseada em múltiplos grafos (semântico, temporal, causal e de entidades), onde a recuperação deixa de ser apenas por similaridade e passa a ser uma travessia guiada pela intenção da pergunta. O resultado são agentes mais coerentes, interpretáveis e capazes de aprender com a experiência ao longo do tempo.
Termos e conceitos
RAG – RAG é uma técnica que permite a um modelo de linguagem consultar informação externa relevante antes de responder.
Agente de IA – Um agente é um sistema de IA que observa o ambiente, toma decisões e executa ações de forma autónoma para atingir um objetivo.
LLM – Um LLM (Large Language Model) é um modelo de inteligência artificial treinado com grandes volumes de texto para compreender e gerar linguagem natural.
Tokens – Tokens são os pequenos blocos de texto em que uma frase é dividida para que a IA a consiga compreender.
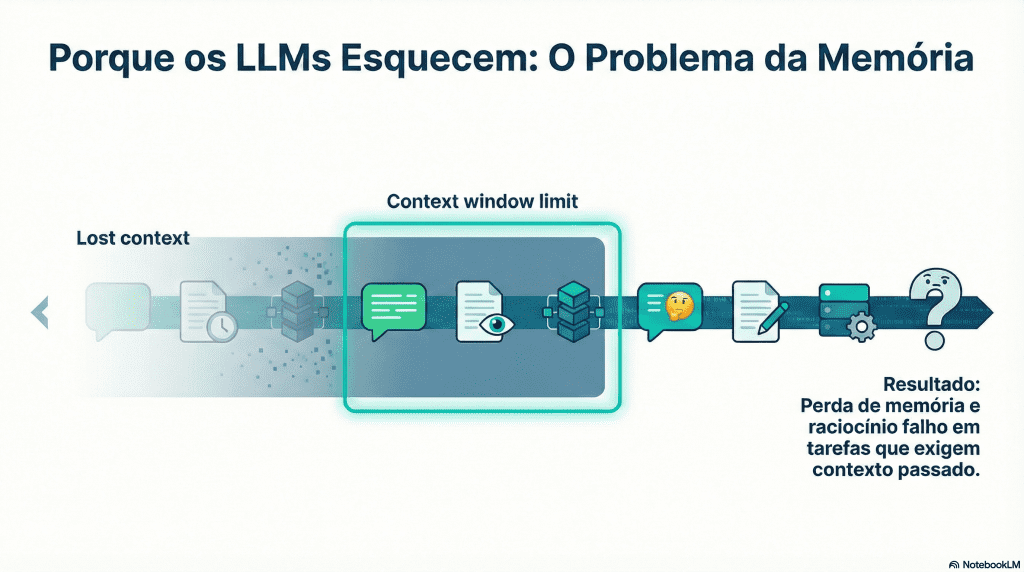
Porque é que a memória continua a ser o “calcanhar de Aquiles” da IA
O Problema da Memória dos LLMs
Os modelos de linguagem atuais são impressionantes. Conseguem escrever código, explicar conceitos complexos e manter diálogos convincentes. Mas basta prolongar a conversa, mudar ligeiramente o contexto ou regressar a um tema passado para que surja um problema recorrente: a memória falha.
Apesar de toda a sofisticação, os LLMs continuam presos a uma janela de contexto finita. Tudo o que fica fora desse espaço é, na prática, esquecido. Isto limita drasticamente a sua capacidade de:
Raciocinar sobre sequências longas de eventos
Manter coerência ao longo do tempo
Desenvolver uma identidade estável
Aprender com experiências passadas
A resposta habitual tem sido “mais contexto” ou “mais tokens”. Mas isso é apenas um paliativo. O problema não é só quanto o modelo consegue ver — é como a memória é representada, organizada e recuperada.
É neste ponto que entra o MAGMA, uma proposta que não tenta esticar o contexto, mas sim repensar a memória desde a raiz.
O estado da arte: como funcionam hoje os sistemas de memória para agentes
Memory-Augmented Generation (MAG)
Memória de IA Abordagem Estruturada
Para ultrapassar os limites do contexto, surgiram sistemas de Memory-Augmented Generation. A ideia é simples: em vez de depender apenas da memória implícita do modelo, usa-se uma memória externa onde se guardam interações passadas, documentos ou observações.
Quando surge uma nova pergunta, o sistema:
Procura na memória conteúdos “relevantes”
Injeta essa informação no contexto do modelo
Gera a resposta
Este paradigma abriu a porta a agentes mais persistentes, mas rapidamente revelou fragilidades.
Abordagens dominantes e os seus limites
A maioria das soluções atuais partilha características comuns:
Memória monolítica: tudo vai para o mesmo repositório
Recuperação por similaridade semântica: embeddings + top-k
Heurísticas simples: recência, pontuação, filtros
O problema é que nem todas as perguntas são semânticas.
Perguntas como:
“O que levou a esta decisão?”
“O que aconteceu antes disto?”
“Quem esteve envolvido?”
“Porque é que isto correu mal da última vez?”
exigem estrutura temporal, causal e relacional, algo que embeddings densos não capturam bem.
O resultado é familiar: recuperações vagas, contexto irrelevante e raciocínio frágil especialmente em tarefas longas.
A ideia central do MAGMA
MAGMA Arquitetura de Memória e Grafos
O MAGMA parte de uma premissa simples, mas poderosa:
A memória não deve ser representada num único espaço.
Em vez de tratar todas as memórias como vetores num mesmo embedding, o MAGMA propõe que cada memória seja vista através de múltiplas lentes, cada uma capturando um tipo diferente de relação.
Essas lentes são materializadas como grafos distintos, mas interligados.
Arquitetura do MAGMA: memória como múltiplos grafos
Uma Memória Múltiplas Vistas
O que é um item de memória?
No MAGMA, um item de memória pode ser:
Uma interação
Uma observação
Um evento
Uma decisão tomada pelo agente
Esse item existe simultaneamente em vários grafos, cada um com ligações diferentes.
Os quatro grafos fundamentais
Grafo Semântico
Captura o significado do conteúdo. É o mais próximo das abordagens tradicionais de embeddings, ligando memórias por similaridade conceptual.
Serve bem para:
Perguntas factuais
Recuperação de conhecimento
Grafo Temporal
Modela quando algo aconteceu.
As ligações representam:
Ordem dos eventos
Distância temporal
Continuidade histórica
Essencial para perguntas do tipo:
“O que aconteceu antes?”
“O que mudou desde então?”
Grafo Causal
Representa relações de causa-efeito.
Aqui, os nós ligam-se porque:
Um evento levou a outro
Uma decisão teve consequências
Este grafo é crítico para:
Raciocínio explicativo
Análise de erros
Planeamento futuro baseado no passado
Grafo de Entidades
Organiza memórias em torno de:
Pessoas
Objetos
Conceitos
Tópicos
Permite responder a:
“Quem esteve envolvido?”
“O que já sabemos sobre X?”
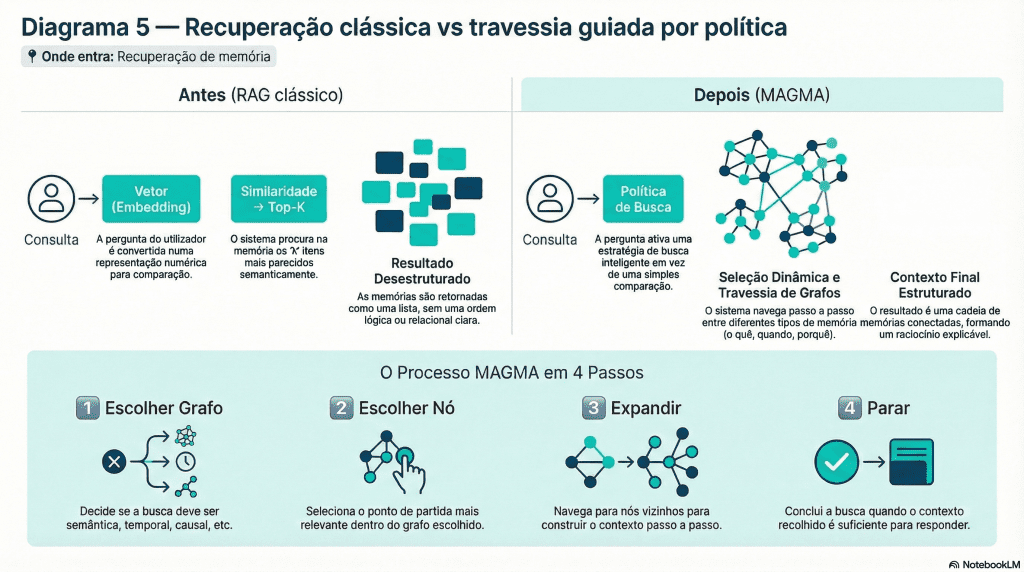
Recuperação de memória como travessia guiada por política
Recuperação Clássica Versus Processo MAGMA
Porque a similaridade não chega
Num sistema clássico, a pergunta é convertida num embedding e comparada com a memória. Isto assume que:
A relevância é sempre semântica
O melhor contexto está nos itens mais “parecidos”
Mas a intenção real da pergunta pode ser temporal, causal ou relacional.
O novo paradigma do MAGMA
O MAGMA reformula a recuperação como um problema de decisão sequencial:
Uma política decide:
Qual o grafo a explorar
Que nós visitar
Quando parar
Em vez de “os 5 mais parecidos”, temos uma travessia adaptativa, guiada pela intenção da query.
O sistema pode, por exemplo:
Começar no grafo semântico
Saltar para o grafo causal
Refinar no grafo temporal
Interpretabilidade como vantagem estrutural
Uma consequência importante: o caminho percorrido é explícito.
Isto permite:
Entender porque certa memória foi usada
Depurar erros
Ajustar o comportamento do agente
Algo praticamente impossível em pipelines puramente baseados em embeddings.
Separar memória de raciocínio: uma escolha crítica
MAGMA Raciocínio Explícito e Interpretável
Uma das decisões arquiteturais mais relevantes do MAGMA é o desacoplamento entre:
Representação da memória
Lógica de recuperação
A memória é estrutural e persistente. A política de recuperação é flexível e adaptável.
Este design traz benefícios claros:
Maior controlo
Melhor extensibilidade
Menos interferência entre tipos de informação
Resultados experimentais
O MAGMA foi avaliado em benchmarks focados em raciocínio de longo prazo, como LoCoMo e LongMemEval.
Os resultados mostram:
Melhor desempenho global
Menor degradação ao longo do tempo
Maior coerência entre sessões
Mais importante do que a métrica bruta é o comportamento emergente: o agente mantém contexto, aprende com o passado e evita repetir erros.
Porque o MAGMA é diferente (e importante)
MAGMA Memória e Lógica Separada
O MAGMA não é apenas “mais um RAG”.
É uma mudança de mentalidade:
De memória implícita para memória explícita
De similaridade para estrutura
De contexto temporário para experiência acumulada
Isto aproxima os agentes de conceitos como:
Identidade
Continuidade
Aprendizagem experiencial
Limitações e desafios abertos
Claro que há desafios:
Custos computacionais dos grafos
Escalabilidade a milhões de memórias
Aprendizagem eficiente da política
Integração com agentes existentes
Mas estes são problemas de engenharia, não limitações conceptuais.
O futuro da memória em agentes de IA
Memória Estruturada Potencia a Inteligência
Se queremos agentes que:
Trabalhem durante meses
Evoluam com o utilizador
Tomem decisões informadas pelo passado
então a memória tem de ser uma infraestrutura central, não um acessório.
O MAGMA não é o ponto final, mas é um passo sólido na direção certa.
Conclusão
Sem memória estruturada, não há agentes inteligentes de longo prazo.
O MAGMA mostra que o caminho não passa por janelas de contexto maiores, mas por memórias melhor organizadas, relacionais e interpretáveis.
É uma proposta ambiciosa e precisamente por isso, relevante.
FAQs — Memória em Agentes de IA e MAGMA
O que é memória em agentes de IA?
A memória em agentes de IA refere-se à capacidade de armazenar, organizar e reutilizar informação ao longo do tempo, para além da janela de contexto imediata de um modelo de linguagem. É essencial para agentes que operam em múltiplas sessões, tomam decisões sequenciais ou precisam de manter coerência a longo prazo.
Porque é que os LLMs têm problemas de memória?
Os LLMs funcionam com uma janela de contexto finita. Tudo o que fica fora desse contexto deixa de influenciar a resposta. Sem memória externa estruturada, o modelo não consegue recordar decisões passadas, eventos antigos ou relações causais complexas.
O que é o RAG clássico e porque não é suficiente?
O RAG (Retrieval-Augmented Generation) clássico recupera informação com base em similaridade semântica usando embeddings. Funciona bem para perguntas factuais, mas falha quando a pergunta é:
temporal (“o que aconteceu antes?”)
causal (“porque é que isto falhou?”)
relacional (“quem esteve envolvido?”)
Nestes casos, a estrutura da memória é mais importante do que a semântica.
O que é o MAGMA?
O MAGMA é uma arquitetura de memória para agentes de IA baseada em múltiplos grafos. Cada item de memória é representado simultaneamente em diferentes grafos, permitindo raciocínio semântico, temporal, causal e baseado em entidades.
Que tipos de grafos o MAGMA utiliza?
O MAGMA organiza a memória em quatro grafos principais:
Semântico — significado e conteúdo
Temporal — ordem e recência dos eventos
Causal — relações de causa-efeito
Entidades — pessoas, objetos e conceitos envolvidos
Cada grafo oferece uma “vista” diferente sobre a mesma memória.
Como funciona a recuperação de memória no MAGMA?
Em vez de recuperar os itens mais semelhantes semanticamente, o MAGMA usa uma política de decisão que guia uma travessia pelos grafos. O sistema decide:
que grafo explorar
que nós visitar
quando parar
A recuperação adapta-se à intenção da pergunta.
O que significa dizer que o MAGMA é interpretável?
Significa que é possível ver o caminho de raciocínio usado para recuperar memórias: quais os nós visitados, que relações foram seguidas e porque certas memórias foram escolhidas. Isto facilita debugging, controlo e confiança no sistema.
O MAGMA substitui o RAG?
Não necessariamente. O MAGMA pode complementar ou evoluir sistemas RAG existentes. Enquanto o RAG clássico é eficaz para recuperação documental, o MAGMA é mais adequado para memória experiencial e raciocínio de longo prazo em agentes.
Para que tipos de aplicações o MAGMA é mais útil?
O MAGMA é especialmente relevante para:
agentes autónomos
assistentes pessoais de longo prazo
sistemas multi-sessão
agentes que aprendem com a experiência
aplicações onde coerência e continuidade são críticas
Quais são os principais desafios desta abordagem?
Alguns desafios ainda em aberto incluem:
escalabilidade dos grafos
custos computacionais
aprendizagem eficiente da política de travessia
integração com arquiteturas existentes
Apesar disso, são sobretudo desafios de engenharia, não limitações conceptuais.
A memória baseada em grafos é o futuro dos agentes de IA?
Tudo indica que sim, ou pelo menos uma parte central desse futuro. À medida que os agentes passam de respostas pontuais para comportamentos persistentes, a memória estruturada deixa de ser opcional e passa a ser infraestrutura cognitiva.









.jpg?itok=2tM9Sm-8)